LangChain Conversational Memory Comparison
AI LLM LangChain
Last updated on
This article will provide you quick comparison of different conversation memory in LangChain. You may find all the available memory types in LangChain in langchain 0.1.16 — 🦜🔗 LangChain 0.1.16
langchain-conversational-memory.ipynb
Getting Started
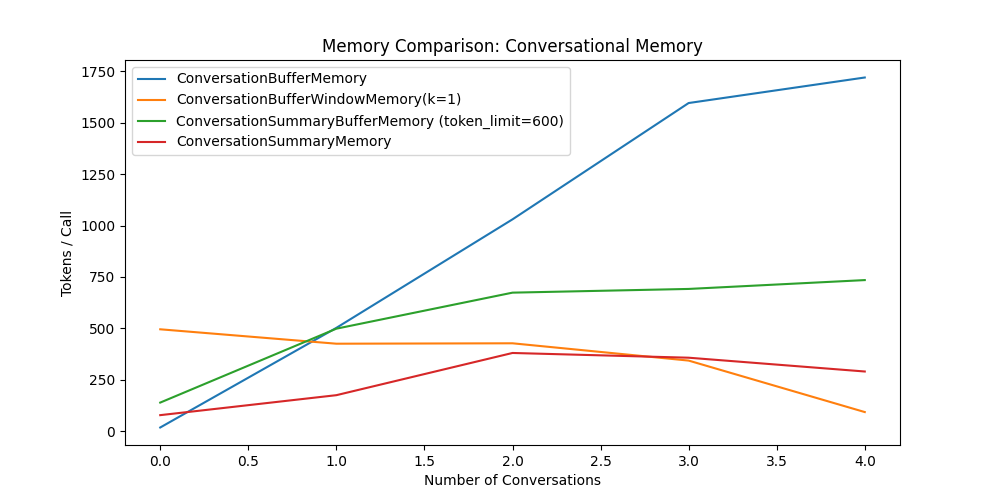
We will loop through the conversations and count the tokens spent for each conversation, save the memory token comparison in memory_token_comparison, finally we will plot the line graph to compare the memory types.
from langchain_community.llms.ollama import Ollama
llm = Ollama()
# Count tokens spent function
from langchain.chains.conversation.base import ConversationChain
from langchain_core.messages import get_buffer_string
def count_tokens(chain: ConversationChain, query: str) -> tuple:
response = chain.invoke(query)
buffer = chain.memory.buffer
token_spent = chain._get_num_tokens(buffer)
print(f"Spent {token_spent} tokens")
return (response, token_spent)
conversations = [
"Good morning AI!",
"My interest here is to explore the potential of integrating Large Language Models with external knowledge",
"I just want to analyze the different possibilities. What can you think of?",
"Which data source types could be used to give context to the model?",
"What is my aim again?",
]
memory_token_comparison = []
ConversationChain without memory
from langchain.chains.conversation.base import ConversationChain
conversation = ConversationChain(llm=llm)
print(conversation.prompt.template)
Prompt template
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
{history}
Human: {input}
AI:
ConversationBufferMemory
Remember everything.
# ConversationChain with buffer memory
from langchain.chains.conversation.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="history", return_messages=False)
conversation_buf = ConversationChain(llm=llm, memory=memory)
for index, query in enumerate(conversations):
response, token_spent = count_tokens(conversation_buf, query)
memory_token_comparison.append(("ConversationBufferMemory", index, token_spent))
ConversationSummaryMemory
Summary each conversation.
# ConversationChain with summary memory (summary before passed into {history} prompt)
from langchain.chains.conversation.memory import ConversationSummaryMemory
memory = ConversationSummaryMemory(llm=llm)
conversation_sum = ConversationChain(llm=llm, memory=memory)
for index, query in enumerate(conversations):
response, token_spent = count_tokens(conversation_sum, query)
memory_token_comparison.append(("ConversationSummaryMemory", index, token_spent))
Memory prompt template for summarize conversation.
Progressively summarize the lines of conversation provided, adding onto the previous summary returning a new summary.
EXAMPLE
Current summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good.
New lines of conversation:
Human: Why do you think artificial intelligence is a force for good?
AI: Because artificial intelligence will help humans reach their full potential.
New summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good because it will help humans reach their full potential.
END OF EXAMPLE
Current summary:
{summary}
New lines of conversation:
{new_lines}
New summary:
ConversationBufferWindowMemory
Only remember the last k conversation.
# ConversationChain with window memory
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(k=1)
conversation_bufw = ConversationChain(llm=llm, memory=memory)
for index, query in enumerate(conversations):
response, token_spent = count_tokens(conversation_bufw, query)
memory_token_comparison.append(
("ConversationBufferWindowMemory(k=1)", index, token_spent)
)
ConversationSummaryBufferMemory
If buffer history hit the token limit, it will summarize the conversation.
# ConversationChain with summary buffer memory
from langchain.chains.conversation.memory import ConversationSummaryBufferMemory
memory = ConversationSummaryBufferMemory(
memory_key="history",
return_messages=False,
llm=llm,
max_token_limit=600,
)
conversation_sum_buf = ConversationChain(llm=llm, memory=memory)
for index, query in enumerate(conversations):
response, token_spent = count_tokens(conversation_sum_buf, query)
memory_token_comparison.append(
("ConversationSummaryBufferMemory (token_limit=600)", index, token_spent)
)
Result
# plot the token comparison in line graph
import matplotlib.pyplot as plt
import pandas as pd
df = pd.DataFrame(memory_token_comparison, columns=["Memory", "Index", "Tokens"])
plt.figure(figsize=(10, 5))
for memory, tokens in df.groupby("Memory"):
plt.plot(tokens["Index"], tokens["Tokens"], label=memory)
plt.xlabel("Number of Conversations")
plt.ylabel("Tokens / Call")
plt.legend()
plt.show()